DuetBench: An evaluation of self-improving customer service agents
Posted on June 9, 2026


Article
Today, we launched Duet Autopilot, the first verified self-improving agent for customer experience. As an always-on partner, Autopilot translates signals from production conversations into validated agent updates, staged for human review. In beta, teams accepted 93% of the proposed workspaces after review, showing that Autopilot produced production-ready agent updates.
Self-improvement claims require measurable evidence: are the proposed changes actually making the agent better? Misaligned suggestions can lead teams toward superficial fixes that don't move the needle on enterprise KPIs. To validate Autopilot’s impact, we built a new evaluation framework.
We call it DuetBench, the first benchmark in the customer service domain designed to evaluate agent self-improvement.
A paradigm shift in roles: From agent builders to agent managers
For the first time in Decagon’s history, Duet is performing more agent-building work than humans. In the past week, Duet created 81% of test simulations and made 54% of agent edits.
This transitions the human role from manual agent builder to agent manager. Teams still define goals, review proposed changes, and decide what moves into production. But more of the diagnostic, testing, and editing work now happens automatically.
.png)
That makes DuetBench the critical control point, where a shift in who does the work only matters if the automated work is right.
Why a new benchmark?
DuetBench fills a gap in how conversational AI agents are evaluated. Existing benchmarks measure whether an agent can resolve a fixed set of issues, but they don’t yet measure the improvement loop. Three gaps stand out:
- Static: They test single-issue resolution against a frozen snapshot, not the dynamic, iterative work that happens in practice.
- Effort-blind: They measure final scores, not the ability to self-improve. An agent may score well on static benchmarks while still requiring constant maintenance, the real bottleneck for enterprises.
- Lacking real-world complexity: They operate in simplified environments that don't reflect production reality. Tasks focus on instruction-following and tool use instead of debugging poor conversations, fixing agent logic, and stress-testing changes.
By contrast, DuetBench measures whether Autopilot can make verifiable agent improvements, rather than producing plausible-looking changes.
Methodology
We designed an evaluation harness that mirrors real-world enterprise agent building. DuetBench runs on simulated customer deployments, complete with Agent Operating Procedures (AOPs), tools, guardrails, and synthetic traffic, so Autopilot faces the same messy edge cases teams encounter in production. For experiments with a human baseline, we compared Autopilot against recently certified Decagon employees who had completed Decagon Masters, our agent-building certification program.
DuetBench evaluates Autopilot across four experiment families that map to the full agent improvement loop: diagnostic tasks, build tasks, simulation-generation tasks, and end-to-end certification tasks. Together, they measure whether Autopilot can identify the right problem, build AOPs, validate the change, and perform the full workflow at the same bar Decagon uses to evaluate human agent builders.
Results
Duet Autopilot passed 93% of diagnostic tasks, exceeding the average human score
Accurately identifying issues and improvement opportunities sets the trajectory for every downstream impact. A misdiagnosis optimizes the wrong objective, sending the entire improvement loop in the wrong direction.
We tested Autopilot on 90 diagnostic tasks across nine families, from calculating metrics to root-causing CSAT drops amid complex mix shifts and experiment rollouts. Tasks range from a one-minute lookup to a full-hour investigation, with a median of 15 minutes. Each was graded on multiple verifiable checks; Autopilot had to reach the right answer and use the correct methodology.
Autopilot passed every check on 93% of tasks, outperforming the 83% average human score. On the hardest tasks, it maintained an 87% pass rate.
.png)
Autopilot also showed strong resilience to sycophancy, the tendency to agree with unsupported claims, refuting 100% of sycophancy attempts. Across tasks, Autopilot averaged 13 tool calls and used up to 64 on the hardest investigations, grounding each conclusion in evidence rather than deference.
Duet Autopilot outperformed humans on timed enterprise agent-building tasks, especially as task complexity increased
Building an AOP means handling every path a conversation can take for a given intent, not just the happy path. DuetBench assessed Autopilot on 44 agent-building tasks that mirror real enterprise workflows. Starting from messy design documents, Autopilot had to build the AOP and its tools from scratch, then generate and pass simulations across diverse scenarios. A build task passed only if every associated simulation passed.
Autopilot passed 45.5% of build tasks compared to a 23% human pass rate for work completed within 3 hours. Notably, humans completed none of the medium or hard tasks in that window, while Autopilot finished 57.1% of medium tasks and 30.8% of hard tasks, all within 60 minutes and without human supervision.
.png)
Autopilot reliably drives the zero-to-one agent build to completion, producing high-quality AOPs that handle diverse pathways, complex logic, and real-world tool calls. This performance stems from its self-improvement loop: Autopilot runs simulations, identifies broken branches, and repairs the AOP or underlying tool, converging in roughly 2.2 rounds.
Duet Autopilot validated its own test set, improving simulation accuracy after each round of self-critique
For Autopilot to improve agents reliably, it needs to be a trustworthy self-critic capable of validating its own test set before proposing changes for review.
DuetBench tested this across 20 AOPs and 520 runs. On the first pass, Autopilot’s generated simulations were 58% accurate. After self-critique, accuracy rose to 88%, cutting false results by more than two-thirds. Autopilot also surfaced genuine bugs in 70% of benchmark scenarios.
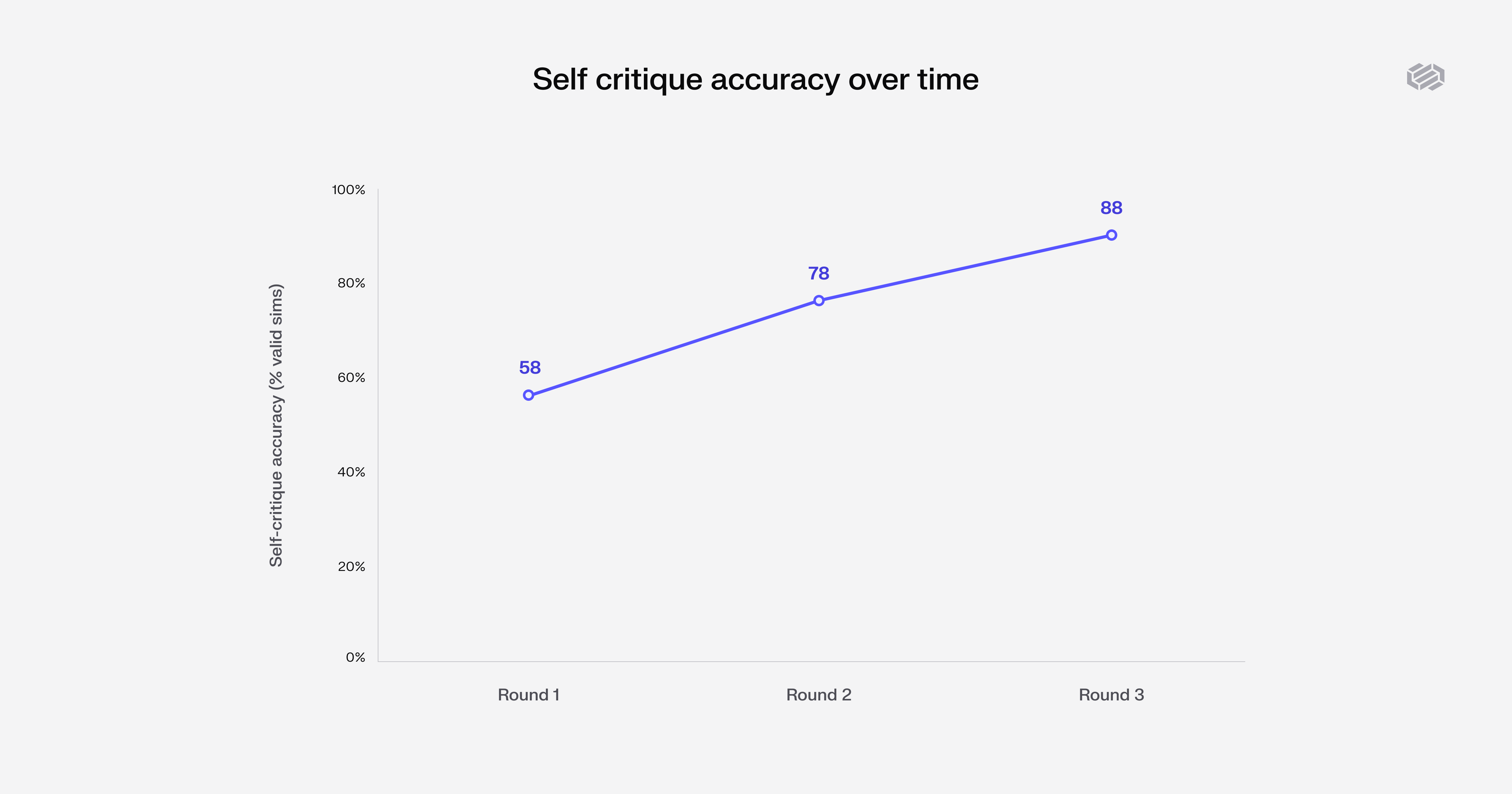
This matters because the quality of the test set determines the quality of the improvement loop. By validating its own simulations before escalating findings, Autopilot keeps proposed changes grounded in real failures instead of noise.
Duet Autopilot reached the certification standard for human agent builders
The previous sections measure each capability in isolation: diagnosing issues, building fixes, and constructing tests. To evaluate whether those skills hold together end-to-end, DuetBench includes Decagon Masters, an intensive certification program for internal employees.
Decagon Masters is a rigorous assessment of real agent-building work. A new human agent builder typically spends six to eight hours on one of the three sections alone. Held to the same bar, Autopilot reached the 90% pass rate used to certify humans.
.png)
The assignments are intentionally complex. For example, one question requires classifying a user’s issue with a tool, routing each category with exact scripting, escalating out-of-scope cases, clarifying unclear requests, and avoiding re-triggering an earlier authentication flow, all in a single pass/fail task.
Reaching Decagon’s human certification bar shows that Autopilot’s capabilities hold together across the full improvement loop, not just in isolation.
What’s next
DuetBench shows that Autopilot can diagnose, improve, and test customer service agents at or above average human performance across core agent-building tasks. That changes the operating model for enterprise AI teams: humans define goals, review proposed changes, and decide what moves into production, while Autopilot handles more of the diagnostic, testing, and editing work required to improve agents over time.
A self-improving agent is only worth deploying if its output is trustworthy. That is what DuetBench measures: whether Autopilot can make verifiable agent improvements rather than producing plausible-looking changes. Verified this way, Autopilot gains become a new way for enterprises to operate, maintain, and continuously improve customer-facing AI agents.
At Decagon, we’re excited to partner with global enterprises on their AI transformation journeys. We’re transforming customer experience, and that includes giving organizations the platform and tools to build, manage, and continuously improve their agents.
To learn more about Duet Autopilot, book a demo. To help build the future of self-improving agents, join our research team.

Start improving your workflow with Decagon
With Decagon, CX teams don’t have to guess whether a change will improve CSAT or deflection. They can move quickly, measure what matters, and act on what works.
Join us
There are very few places where you can prototype with frontier LLMs, ship to production in days, and watch users engage with the systems you built—all while owning the entire stack, from intent parsing and tool usage to API integration and observability. This role at Decagon is one of those places.
From my own experience working across both agent development and broader engineering initiatives at Decagon, I’ve seen firsthand how uniquely impactful this work can be. Whether I’m building intelligent workflows for customers or designing infrastructure that supports our agent platform, it’s rare to find an environment where the work transitions from concept to production within days, actively powering user experiences and transforming how businesses operate.
If you’re looking for a role where you can:
- Build at the frontier of LLMs, automation, and user interaction
- Deploy AI agents that solve high-value business use cases across industries including retail, travel and hospitality, fintech, edtech, and more
- Work directly with customers on high-impact use cases
- Ship fast, iterate constantly, and own your work from idea to production
- Join a fast-moving, collaborative team solving real-world challenges with AI
We’d love to hear from you!
.png)



.svg)

.svg)

.svg)

.svg)

.svg)

.svg)

.svg)
The AI concierge for every customer.